Chapter 6 Importing, Modifying, and Filtering Data
6.1 Separate raw and clean data folders
Cleaning or tidying data is the most important first step in starting any data analysis, modeling, or even visualization project. At the beginning of our analysis, we have raw data from our surveys, experiments, instruments, or of course, hastily put together web-scraping operations. And after cleaning our data, we have tidy data which we can easily work and operate on. So, we have raw data which is often poorly unstructured and we have tidy data which is clean and well structured, ready for analysis.
There’s a great quote from Hadley Wickham on the subject: “Tidy datasets are all alike but every messy dataset is messy in its own way.” This is why data science is often said to be 80% data cleaning and 20% doing fun stuff, but because so much effort has to be put into tidying data, it is crucial that you do not throw away the tidying process. It’s a crucial component of your analysis and required for fully reproducible research or analysis.
So, how should we structure our projects to contain both raw and tidy data? Well here’s a fictitious R project called ‘Controversial-Results’ that has been designed so that others can completely replicate the results.
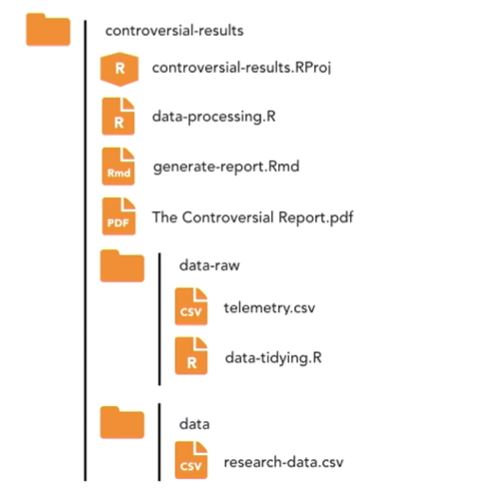
There’s a folder in here called ‘data-raw’ which contains the raw or messy data in the ‘telemetry.csv’ file, and the code for tidying and cleaning the data is stored within the ‘data-tidying.R’ file. At the bottom of this code file, the read R library from the tidyverse is used to write out a tidied version of this data called ‘research-data.csv’ and this is stored inside of a ‘data’ folder. Then in the project root directory, we see there’s a ‘data-processing.R’ file and a ‘generate-report.Rmd’ file which only operates on a tidy data in the ‘data folder’.
If there’s any raw data which needs to be processed, it’s in data-raw. There’s a file there which tidies it together and outputs it into a data folder which is where we have a nice, tidy data which we then use in our data-processing files.