Chapter 4 Influence Diagrams
An influence diagram is: - a directed acyclic graph G containing decision and chance nodes, and information and relevance arcs representing what is known at the time of a decision and probabilistic dependency, respectively. - a set of probability distributions associated with each chance node, - optionally a utility node and a corresponding set of utilities
4.1 Umbrella Problem
Consider the case when you are getting out of your apartment and you want to decide whether to take an umbrella with you or not. Your decision is certainly dependent on the weather, a phenomenon you cannot control. For simplicity, assume the weather can get one of the two states: sunshine or rain. You have likes and dislikes about taking your umbrella with you (you care!) depending on the weather. If it turns out to be a sunny day and you have taken your umbrella with you, you don’t like it. However, you would hate it more if it rains and you do not have your umbrella. You are happier if it is sunny and you have left your umbrella at home (do not need to carry it around). You are happiest if it rains and you have your umbrella with you.
library(HydeNet)
umbrella.net <- HydeNetwork(~ payoff | action*weather)For the chance node ‘weather’:
weather_prob <- c(0.3, 0.7) #Prior probability for rain and sunshine, respectively.
umbrella.net <- setNode(umbrella.net, weather, nodeType="dcat", pi=vectorProbs(p=weather_prob, weather), factorLevels = c("rain","sunshine"), validate = FALSE)For the decision nodes ‘action’:
dprob <- c(1,0) #Probability of decision nodes represent do and don't.
umbrella.net <- setNode(umbrella.net, action, nodeType="dcat", pi=vectorProbs(p=dprob, action), factorLevels = c("take","leave"), validate = FALSE)For the utility node ‘payoff’:
umbrella.net <- setNode(umbrella.net, payoff, "determ", define=fromFormula(),
nodeFormula = payoff ~ ifelse(weather == "rain",
ifelse(action == "take", 100, 0),
ifelse(action == "take", 30, 70)))
umbrella.net <- setDecisionNodes(umbrella.net, action) #Setting the decision nodes
umbrella.net <- setUtilityNodes(umbrella.net, payoff) #Setting the utility nodes
plot(umbrella.net) #Plotting the influence diagram of extended version of oil-wildcatter problem4.1.1 Finding the optimal policy
Let us pass this structure to the Gibbs sampler (JAGS) and track the variables of interest (these nodes are useful to compute the conditional expectations if necessary).
Please note that the rjags package is just an interface to the JAGS library. Make sure you have installed JAGS-4.exe (can be downloaded from here)
We are trying to compute the expected utility of the policy: (‘action’).
HydeNet provides a policyMatrix() function to enumerate all policies of a given decision network. This decision network is solved using Gibbs sampling with 10^6 samples. We could use them as follows:
policy_umbrella <- policyMatrix(umbrella.net)
compiledNet_umbrella <- compileDecisionModel(umbrella.net, policyMatrix = policy_umbrella)## Compiling model graph
## Resolving undeclared variables
## Allocating nodes
## Graph information:
## Observed stochastic nodes: 0
## Unobserved stochastic nodes: 2
## Total graph size: 16
##
## Initializing model
##
## Compiling model graph
## Resolving undeclared variables
## Allocating nodes
## Graph information:
## Observed stochastic nodes: 1
## Unobserved stochastic nodes: 1
## Total graph size: 16
##
## Initializing model
##
## Compiling model graph
## Resolving undeclared variables
## Allocating nodes
## Graph information:
## Observed stochastic nodes: 1
## Unobserved stochastic nodes: 1
## Total graph size: 16
##
## Initializing modeltrackedVars_umbrella <- c("weather","action","payoff")
samples_umbrella <- lapply(compiledNet_umbrella,
HydeSim,
variable.names = trackedVars_umbrella,
n.iter = 10^5)Let us compute a single utility on samples:
samples_umbrella <- lapply(samples_umbrella, function(x)
cbind(x, utility = x$payoff))Now we can view all expectations at once by combining policies and the computed expectations:
results_umbrella <- lapply(samples_umbrella, function(l) mean(l$utility))
results_umbrella <- as.data.frame(unlist(results_umbrella))
results_umbrella <- cbind(policy_umbrella, results_umbrella)
colnames(results_umbrella)[ncol(policy_umbrella)+1] <- "utility"The results according policies are given below:
results_umbrella[]## action utility
## 1 1 50.9230
## 2 2 48.9384According to the policies, all utility values seem feasible and we don’t have any conceptual error in the model. The optimal policy seems to be:
results_umbrella[results_umbrella$utility == max(results_umbrella$utility),] ## action utility
## 1 1 50.923..the first policy which means DO the ‘action’, or TAKE the UMBRELLA which results in an expected reward of app. 51.2%.
As extra information to be obtained from the output (to double check the validity of this model in this case),
Among the cases where it is decided not to ?drill? (3,4,7 and 8), it is sensible that the decision of not doing ?test? and not doing ?recovery? must be taken. It is clearly seen from result table. So when you do drill, you simply do not ?test?. The utility results can be seen from the following table:
lapply(samples_umbrella, function(l) mean(l[l$weather=="rain",]$utility))## [[1]]
## [1] 100
##
## [[2]]
## [1] 0lapply(samples_umbrella, function(l) mean(l[l$weather=="sunshine",]$utility))## [[1]]
## [1] 30
##
## [[2]]
## [1] 704.1.1.1 Evaluating Influence Diagrams: Augmented Variable Elimination
- Barren node removal: A barren node may be simply removed from an oriented, regular influence diagram. If it is a decision node, then any alternative would be optimal.
- Chance node removal: Given that chance node X directly precedes the value node and nothing else in an oriented, regular ID, node X can be removed by conditional expectation. Afterward, the value node inherits all of the conditional predecessors from node X, and thus the process creates no new barren nodes.
- Decision node removal: Given that all barren nodes have been removed, that decision node A is a conditional predecessor of the value node, and that all other conditional predecessors of the value node are informational predecessors of node A in an oriented, regular ID, node A may be removed by maximizing expected utility, conditioned on the values of its informational predecessors. The maximizing alternative(s) should be recorded as the optimal policy.
- Arc reversal: (between chance nodes). As we have seen before.
4.2 Incorporating Weather Forecast
Consider the umbrella problem. Assume that you now decided to make a more informed decision. You listen to a weather forecast for that day. The new situation is depicted as:
library(HydeNet)
umbrella2.net <- HydeNetwork(~ payoff | action*weather
+ action | weather_forecast
+ weather_forecast | weather)For the chance node ‘weather’:
weather_prob <- c(0.3,0.7) #Prior probability for rain and sunshine, respectively.
umbrella2.net <- setNode(umbrella2.net, weather, nodeType="dcat", pi=vectorProbs(p=weather_prob, weather), factorLevels = c("rain","sunshine"), validate = FALSE)For the chance node ‘weather_forecast’:
cpt_weather_forecast <- readRDS(url("https://github.com/canaytore/bayesian-networks/raw/main/data/cpt_weather_forecast.rds"))
#The file ?cpt_weather_forecast.rds? was created using the inputCPT() function of HydeNet. It stands for the conditional probability table of the seismic results based on parent nodes which are 'test' and 'oil_content'.
cpt_weather_forecast## weather_forecast
## weather sunny cloudy rainy
## rain 0.15 0.25 0.6
## sunshine 0.70 0.20 0.1umbrella2.net <- setNodeModels(umbrella2.net, cpt_weather_forecast)For the decision nodes ‘action’:
dprob <- c(1,0) #Probability of decision nodes represent do and don't.
umbrella2.net <- setNode(umbrella2.net, action, nodeType="dcat", pi=vectorProbs(p=dprob, action), factorLevels = c("take","leave"), validate = FALSE)For the utility node ‘payoff’:
umbrella2.net <- setNode(umbrella2.net, payoff, "determ", define=fromFormula(),
nodeFormula = payoff ~ ifelse(weather == "rain",
ifelse(action == "take", 100, 0),
ifelse(action == "take", 30, 70)))
umbrella2.net <- setDecisionNodes(umbrella2.net, action) #Setting the decision nodes
umbrella2.net <- setUtilityNodes(umbrella2.net, payoff) #Setting the utility nodes
plot(umbrella2.net) #Plotting the influence diagram of extended version of oil-wildcatter problem4.2.1 Finding the optimal policy
Let us pass this structure to the Gibbs sampler (JAGS) and track the variables of interest (these nodes are useful to compute the conditional expectations if necessary).
Please note that the rjags package is just an interface to the JAGS library. Make sure you have installed JAGS-4.exe (can be downloaded from here)
We are trying to compute the expected utility of the policy: (‘action’).
HydeNet provides a policyMatrix() function to enumerate all policies of a given decision network. This decision network is solved using Gibbs sampling with 10^6 samples. We could use them as follows:
policy_umbrella2 <- policyMatrix(umbrella2.net)
compiledNet_umbrella2 <- compileDecisionModel(umbrella2.net, policyMatrix = policy_umbrella2)## Compiling model graph
## Resolving undeclared variables
## Allocating nodes
## Graph information:
## Observed stochastic nodes: 0
## Unobserved stochastic nodes: 3
## Total graph size: 26
##
## Initializing model
##
## Compiling model graph
## Resolving undeclared variables
## Allocating nodes
## Graph information:
## Observed stochastic nodes: 1
## Unobserved stochastic nodes: 2
## Total graph size: 26
##
## Initializing model
##
## Compiling model graph
## Resolving undeclared variables
## Allocating nodes
## Graph information:
## Observed stochastic nodes: 1
## Unobserved stochastic nodes: 2
## Total graph size: 26
##
## Initializing modeltrackedVars_umbrella2 <- c("weather","weather_forecast","action","payoff")
samples_umbrella2 <- lapply(compiledNet_umbrella2,
HydeSim,
variable.names = trackedVars_umbrella2,
n.iter = 10^5)Let us compute a single utility on samples:
samples_umbrella2 <- lapply(samples_umbrella2, function(x)
cbind(x, utility = x$payoff))Now we can view all expectations at once by combining policies and the computed expectations:
results_umbrella2 <- lapply(samples_umbrella2, function(l) mean(l$utility))
results_umbrella2 <- as.data.frame(unlist(results_umbrella2))
results_umbrella2 <- cbind(policy_umbrella2, results_umbrella2)
colnames(results_umbrella2)[ncol(policy_umbrella2)+1] <- "utility"The results according policies are given below:
results_umbrella2[]## action utility
## 1 1 50.9783
## 2 2 49.0798According to the policies, all utility values seem feasible and we don’t have any conceptual error in the model. The optimal policy seems to be:
results_umbrella2[results_umbrella2$utility == max(results_umbrella2$utility),] ## action utility
## 1 1 50.9783..the first policy which means DO the ‘action’, or TAKE the UMBRELLA which results in an expected reward of app. 51.2%.
As extra information to be obtained from the output (also to double check the validity of this model in this case),
Among the cases where it is decided not to ?drill? (3,4,7 and 8), it is sensible that the decision of not doing ?test? and not doing ?recovery? must be taken. It is clearly seen from result table. So when you do drill, you simply do not ?test?. The utility results can be seen from the following table:
lapply(samples_umbrella2, function(l) mean(l[l$weather_forecast=="sunny",]$utility))## [[1]]
## [1] 35.86156
##
## [[2]]
## [1] 64.18426lapply(samples_umbrella2, function(l) mean(l[l$weather_forecast=="rainy",]$utility))## [[1]]
## [1] 80.41566
##
## [[2]]
## [1] 19.55854lapply(samples_umbrella2, function(l) mean(l[l$weather_forecast=="cloudy",]$utility))## [[1]]
## [1] 54.75243
##
## [[2]]
## [1] 45.914264.3 Oil-Wildcatter Problem:
An oil wildcatter must decide whether to drill or not to drill. The cost of drilling is $70,000. If he decides to drill, the well may be soaking (with a return of $270,000), wet (with a return of $120,000), or dry (with a return of $0). These returns are exclusive of the drilling cost. The prior probabilities for soaking (lots of oil), wet (some oil), and dry (no oil) are (0.2, 0.3, 0.5). At the cost of $10,000, the oil wildcatter could decide to take seismic soundings of the geological structure at the site to classify the structure as having either no structure ns, open structure, os and closed structure cs. The specifics of the test are given as follows:
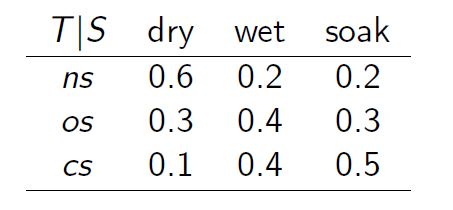
cpt_test
4.3.1 Defining the extended network in HydeNet
Our first task will be to represent and solve the extended oil-wildcatter influence diagram using HydeNet. We generate the network in HydeNet as follows;
library(HydeNet)
ow.net <- HydeNetwork(~ cost | test
+ drill | test*seismic_results
+ seismic_results | test*oil_content
+ reward | drill*oil_content)For the chance node ‘oil_content’:
oil_content_prob <- c(0.5, 0.3, 0.2) #Prior probability for dry, wet and soaking, respectively.
ow.net <- setNode(ow.net, oil_content, nodeType="dcat", pi=vectorProbs(p=oil_content_prob, oil_content), factorLevels = c("dry","wet","soak"), validate = FALSE)For the decision nodes ‘test’ and ‘drill’:
dprob <- c(1,0) #Probability of decision nodes represent do and don't.
ow.net <- setNode(ow.net, test, nodeType="dcat", pi=vectorProbs(p=dprob, test), factorLevels = c("test","dont_test"), validate = FALSE)
ow.net <- setNode(ow.net, drill, nodeType="dcat", pi=vectorProbs(p=dprob, drill), factorLevels = c("drill","dont_drill"), validate = FALSE)For the chance node ‘seismic_results’:
cpt_seismic_results <- readRDS(url("https://github.com/canaytore/bayesian-networks/raw/main/data/cpt_seismic_results.rds"))
#The file ?cpt_seismic_results.rds? was created using the inputCPT() function of HydeNet. It stands for the conditional probability table of the seismic results based on parent nodes which are 'test' and 'oil_content'.
cpt_seismic_results## , , seismic_results = ns
##
## oil_content
## test dry wet soak
## test 0.60 0.20 0.20
## dont_test 0.33 0.33 0.33
##
## , , seismic_results = os
##
## oil_content
## test dry wet soak
## test 0.30 0.40 0.30
## dont_test 0.33 0.33 0.33
##
## , , seismic_results = cs
##
## oil_content
## test dry wet soak
## test 0.10 0.40 0.50
## dont_test 0.34 0.34 0.34ow.net <- setNodeModels(ow.net, cpt_seismic_results)For the utility node ‘cost’:
ow.net <- setNode(ow.net, cost, "determ", define=fromFormula(),
nodeFormula = cost ~ ifelse(test == "test", -10, 0))For the utility node ‘reward’:
ow.net <- setNode(ow.net, reward, "determ", define=fromFormula(),
nodeFormula = reward ~ ifelse(oil_content == "dry",
ifelse(drill == "drill", -70, 0),
ifelse(oil_content == "wet",
ifelse(drill == "drill", 50, 0),
ifelse(drill == "drill", 200, 0))))
ow.net <- setDecisionNodes(ow.net, test, drill) #Setting the decision nodes
ow.net <- setUtilityNodes(ow.net, cost, reward) #Setting the utility nodes
plot(ow.net) #Plotting the influence diagram of extended version of oil-wildcatter problemThe trick is here that we will have precise information about ‘oil_content’ after the decision ‘drill’. Besides, there must be an arc from ?drill? to ?recovery_level? since ‘recovery_level’ should exactly be nr (no recovery) when the drill is not done since it is not sensible to be able to do secondary ‘recovery’ without the primary ‘drill’.
4.3.2 Finding the optimal policy
Let us pass this structure to the Gibbs sampler (JAGS) and track the variables of interest (these nodes are useful to compute the conditional expectations if necessary).
Please note that the rjags package is just an interface to the JAGS library. Make sure you have installed JAGS-4.exe (can be downloaded from here)
We are trying to compute the expected utility of the policy: (‘action’).
HydeNet provides a policyMatrix() function to enumerate all policies of a given decision network. This decision network is solved using Gibbs sampling with 10^6 samples. We could use them as follows:
policy_ow <- policyMatrix(ow.net)
compiledNet_ow <- compileDecisionModel(ow.net, policyMatrix = policy_ow)## Compiling model graph
## Resolving undeclared variables
## Allocating nodes
## Graph information:
## Observed stochastic nodes: 0
## Unobserved stochastic nodes: 4
## Total graph size: 54
##
## Initializing model
##
## Compiling model graph
## Resolving undeclared variables
## Allocating nodes
## Graph information:
## Observed stochastic nodes: 2
## Unobserved stochastic nodes: 2
## Total graph size: 50
##
## Initializing model
##
## Compiling model graph
## Resolving undeclared variables
## Allocating nodes
## Graph information:
## Observed stochastic nodes: 2
## Unobserved stochastic nodes: 2
## Total graph size: 51
##
## Initializing model
##
## Compiling model graph
## Resolving undeclared variables
## Allocating nodes
## Graph information:
## Observed stochastic nodes: 2
## Unobserved stochastic nodes: 2
## Total graph size: 51
##
## Initializing model
##
## Compiling model graph
## Resolving undeclared variables
## Allocating nodes
## Graph information:
## Observed stochastic nodes: 2
## Unobserved stochastic nodes: 2
## Total graph size: 50
##
## Initializing modeltrackedVars_ow <- c("oil_content","seismic_results","test","cost","drill","reward")
samples_ow <- lapply(compiledNet_ow,
HydeSim,
variable.names = trackedVars_ow,
n.iter = 10^5)Let us compute a single utility on samples:
samples_ow <- lapply(samples_ow, function(x)
cbind(x, utility = x$reward + x$cost))Now we can view all expectations at once by combining policies and the computed expectations:
results_ow <- lapply(samples_ow, function(l) mean(l$utility))
results_ow <- as.data.frame(unlist(results_ow))
results_ow <- cbind(policy_ow, results_ow)
colnames(results_ow)[ncol(policy_ow)+1] <- "utility"The results according policies are given below:
results_ow[]## test drill utility
## 1 1 1 9.7369
## 2 2 1 19.9313
## 3 1 2 -10.0000
## 4 2 2 0.0000According to the policies, all utility values seem feasible and we don’t have any conceptual error in the model. The optimal policy seems to be:
results_ow[results_ow$utility == max(results_ow$utility),] ## test drill utility
## 2 2 1 19.9313..the second policy which means DO NOT ‘test’, and DO ‘drill’ which results in an expected reward of app. 19868.3$.
As extra information to be obtained from the output (also to double check the validity of this model in this case),
Among the cases where it is decided not to ?drill? (3,4,7 and 8), it is sensible that the decision of not doing ?test? and not doing ?recovery? must be taken. It is clearly seen from result table. So when you do drill, you simply do not ?test?. The utility results can be seen from the following table:
lapply(samples_ow, function(l) mean(l[l$oil_content=="dry",]$utility))## [[1]]
## [1] -80
##
## [[2]]
## [1] -70
##
## [[3]]
## [1] -10
##
## [[4]]
## [1] 0lapply(samples_ow, function(l) mean(l[l$oil_content=="wet",]$utility))## [[1]]
## [1] 40
##
## [[2]]
## [1] 50
##
## [[3]]
## [1] -10
##
## [[4]]
## [1] 0lapply(samples_ow, function(l) mean(l[l$oil_content=="soak",]$utility))## [[1]]
## [1] 190
##
## [[2]]
## [1] 200
##
## [[3]]
## [1] -10
##
## [[4]]
## [1] 0lapply(samples_ow, function(l) mean(l[l$seismic_results=="ns",]$utility))## [[1]]
## [1] -35.44492
##
## [[2]]
## [1] 20.1213
##
## [[3]]
## [1] -10
##
## [[4]]
## [1] 0lapply(samples_ow, function(l) mean(l[l$seismic_results=="os",]$utility))## [[1]]
## [1] 12.68096
##
## [[2]]
## [1] 19.86737
##
## [[3]]
## [1] -10
##
## [[4]]
## [1] 0lapply(samples_ow, function(l) mean(l[l$seismic_results=="cs",]$utility))## [[1]]
## [1] 73.10689
##
## [[2]]
## [1] 19.80987
##
## [[3]]
## [1] -10
##
## [[4]]
## [1] 04.4 Extended Oil-Wildcatter Problem:
Extend the Oil Wildcatter problem to include the following: After drilling, striking oil, and extracting an optimal amount using primary recovery techniques, the wildcatter has the option of ex- tracting more oil using secondary recovery techniques at an additional cost of $20,000. Secondary recovery will result in no recovery (nr) with associated revenues of $0, low recovery (lr) with associated revenues of $30,000 or high recovery, (hr) with associated revenue of $50,000. The amount of secondary recovery depends on the amount of oil as well. If the well is wet, the conditional probabilities of nr, lr, and hr are 0.5, 0.4 and 0.1, respectively. If the well is soaking, the corresponding probabilities are 0.3, 0.5, 0.2.
4.4.1 Defining the extended network in HydeNet
Our first task will be to represent and solve the extended oil-wildcatter influence diagram using HydeNet. We generate the network in HydeNet as follows;
library(HydeNet)
ow2.net <- HydeNetwork(~ cost | test
+ drill | test*seismic_results
+ seismic_results | test*oil_content
+ reward | drill*oil_content
+ recovery | drill*seismic_results
+ extra_oil_content | oil_content
+ recovery_reward | recovery*extra_oil_content)For the chance node ‘oil_content’:
oil_content_prob <- c(0.5,0.3,0.2) #Prior probability for dry, wet and soaking.
ow2.net <- setNode(ow2.net, oil_content, nodeType="dcat", pi=vectorProbs(p=oil_content_prob, oil_content), factorLevels = c("dry","wet","soak"), validate = FALSE)For the decision nodes ‘test’, ‘drill’ and ‘recovery’:
dprob <- c(1,0) #Probability of decision nodes represent do and don't.
ow2.net <- setNode(ow2.net, test, nodeType="dcat", pi=vectorProbs(p=dprob, test), factorLevels = c("test","dont_test"), validate = FALSE)
ow2.net <- setNode(ow2.net, drill, nodeType="dcat", pi=vectorProbs(p=dprob, drill), factorLevels = c("drill","dont_drill"), validate = FALSE)
ow2.net <- setNode(ow2.net, recovery, nodeType="dcat", pi=vectorProbs(p=dprob, recovery), factorLevels = c("recovery","dont_recovery"), validate = FALSE)For the chance node ‘seismic_results’:
cpt_seismic_results <- readRDS(url("https://github.com/canaytore/bayesian-networks/raw/main/data/cpt_seismic_results.rds"))
#The file ?cpt_seismic_results.rds? was created using the inputCPT() function of HydeNet. It stands for the conditional probability table of the seismic results based on parent nodes which are 'test' and 'oil_content'.
cpt_seismic_results## , , seismic_results = ns
##
## oil_content
## test dry wet soak
## test 0.60 0.20 0.20
## dont_test 0.33 0.33 0.33
##
## , , seismic_results = os
##
## oil_content
## test dry wet soak
## test 0.30 0.40 0.30
## dont_test 0.33 0.33 0.33
##
## , , seismic_results = cs
##
## oil_content
## test dry wet soak
## test 0.10 0.40 0.50
## dont_test 0.34 0.34 0.34ow2.net <- setNodeModels(ow2.net, cpt_seismic_results)For the chance node ‘extra_oil_content’:
cpt_extra_oil_content <- readRDS(url("https://github.com/canaytore/bayesian-networks/raw/main/data/cpt_extra_oil_content.rds"))
#The file ?cpt_recovery_level.rds? was created using the inputCPT() function of HydeNet. It stands for the conditional probability table of the recovery levels based on parent nodes which are 'drill' and 'oil_content'.
#The trick here is that 'recovery_level' should exactly be nr (no recovery) when the drill is not done since it is not sensible to be able to do 'recovery' without the 'drill'.
cpt_extra_oil_content## extra_oil_content
## oil_content nr lr hr
## dry 0.2 0.1 0.7
## wet 0.5 0.4 0.1
## soak 0.3 0.5 0.2ow2.net <- setNodeModels(ow2.net, cpt_extra_oil_content)For the utility node ‘cost’:
ow2.net <- setNode(ow2.net, cost, "determ", define=fromFormula(),
nodeFormula = cost ~ ifelse(test == "test", -10, 0))For the utility node ‘reward’:
ow2.net <- setNode(ow2.net, reward, "determ", define=fromFormula(),
nodeFormula = reward ~ ifelse(oil_content == "dry",
ifelse(drill == "drill", -70, 0),
ifelse(oil_content == "wet",
ifelse(drill == "drill", 50, 0),
ifelse(drill == "drill", 200, 0))))For the utility node ‘recovery_reward’:
ow2.net <- setNode(ow2.net, recovery_reward, "determ", define=fromFormula(),
nodeFormula = recovery_reward ~ ifelse(extra_oil_content == "nr",
ifelse(recovery == "recovery", -20, 0),
ifelse(extra_oil_content == "lr",
ifelse(recovery == "recovery", 10, 0),
ifelse(recovery == "recovery", 30, 0))))
ow2.net <- setDecisionNodes(ow2.net, test, drill, recovery) #Setting the decision nodes
ow2.net <- setUtilityNodes(ow2.net, cost, reward, recovery_reward) #Setting the utility nodes
plot(ow2.net) #Plotting the influence diagram of extended version of oil-wildcatter problemThe trick is here that we will have precise information about ‘oil_content’ after the decision ‘drill’. Besides, there must be an arc from ?drill? to ?recovery_level? since ‘recovery_level’ should exactly be nr (no recovery) when the drill is not done since it is not sensible to be able to do secondary ‘recovery’ without the primary ‘drill’.
4.4.2 Finding the optimal policy
Let us pass this structure to the Gibbs sampler (JAGS) and track the variables of interest (these nodes are useful to compute the conditional expectations if necessary).
Please note that the rjags package is just an interface to the JAGS library. Make sure you have installed JAGS-4.exe (can be downloaded from here)
We are trying to compute the expected utility of the policy: (‘action’).
HydeNet provides a policyMatrix() function to enumerate all policies of a given decision network. This decision network is solved using Gibbs sampling with 10^6 samples. We could use them as follows:
policy_ow2 <- policyMatrix(ow2.net)
compiledNet_ow2 <- compileDecisionModel(ow2.net, policyMatrix = policy_ow2)## Compiling model graph
## Resolving undeclared variables
## Allocating nodes
## Graph information:
## Observed stochastic nodes: 0
## Unobserved stochastic nodes: 6
## Total graph size: 81
##
## Initializing model
##
## Compiling model graph
## Resolving undeclared variables
## Allocating nodes
## Graph information:
## Observed stochastic nodes: 3
## Unobserved stochastic nodes: 3
## Total graph size: 76
##
## Initializing model
##
## Compiling model graph
## Resolving undeclared variables
## Allocating nodes
## Graph information:
## Observed stochastic nodes: 3
## Unobserved stochastic nodes: 3
## Total graph size: 77
##
## Initializing model
##
## Compiling model graph
## Resolving undeclared variables
## Allocating nodes
## Graph information:
## Observed stochastic nodes: 3
## Unobserved stochastic nodes: 3
## Total graph size: 77
##
## Initializing model
##
## Compiling model graph
## Resolving undeclared variables
## Allocating nodes
## Graph information:
## Observed stochastic nodes: 3
## Unobserved stochastic nodes: 3
## Total graph size: 77
##
## Initializing model
##
## Compiling model graph
## Resolving undeclared variables
## Allocating nodes
## Graph information:
## Observed stochastic nodes: 3
## Unobserved stochastic nodes: 3
## Total graph size: 77
##
## Initializing model
##
## Compiling model graph
## Resolving undeclared variables
## Allocating nodes
## Graph information:
## Observed stochastic nodes: 3
## Unobserved stochastic nodes: 3
## Total graph size: 77
##
## Initializing model
##
## Compiling model graph
## Resolving undeclared variables
## Allocating nodes
## Graph information:
## Observed stochastic nodes: 3
## Unobserved stochastic nodes: 3
## Total graph size: 77
##
## Initializing model
##
## Compiling model graph
## Resolving undeclared variables
## Allocating nodes
## Graph information:
## Observed stochastic nodes: 3
## Unobserved stochastic nodes: 3
## Total graph size: 76
##
## Initializing modeltrackedVars_ow2 <- c("oil_content","seismic_results","test","cost","drill","recovery","reward","extra_oil_content","recovery_reward")
samples_ow2 <- lapply(compiledNet_ow2,
HydeSim,
variable.names = trackedVars_ow2,
n.iter = 10^5)Let us compute a single utility on samples:
samples_ow2 <- lapply(samples_ow2, function(x)
cbind(x, utility = x$reward + x$cost + x$recovery_reward))Now we can view all expectations at once by combining policies and the computed expectations:
results_ow2 <- lapply(samples_ow2, function(l) mean(l$utility))
results_ow2 <- as.data.frame(unlist(results_ow2))
results_ow2 <- cbind(policy_ow2, results_ow2)
colnames(results_ow2)[ncol(policy_ow2)+1] <- "utility"The results according policies are given below:
results_ow2[]## test drill recovery utility
## 1 1 1 1 19.8443
## 2 2 1 1 28.7652
## 3 1 2 1 -0.9702
## 4 2 2 1 9.1263
## 5 1 1 2 9.2608
## 6 2 1 2 20.2028
## 7 1 2 2 -10.0000
## 8 2 2 2 0.0000According to the policies, all utility values seem feasible and we don’t have any conceptual error in the model. The optimal policy seems to be:
results_ow2[results_ow2$utility == max(results_ow2$utility),] ## test drill recovery utility
## 2 2 1 1 28.7652..the second policy which means DO NOT ‘test’, DO ‘drill’, and DO ‘recovery’ which results in an expected reward of app. 29254.8$.
As extra information to be obtained from the output (also to double check the validity of this model in this case),
Among the cases where it is decided not to ?drill? (3,4,7 and 8), it is sensible that the decision of not doing ?test? and not doing ?recovery? must be taken. It is clearly seen from result table. So when you do drill, you simply do not ?test?. The utility results can be seen from the following table:
lapply(samples_ow2, function(l) mean(l[l$oil_content=="dry",]$utility))## [[1]]
## [1] -62.06494
##
## [[2]]
## [1] -51.95826
##
## [[3]]
## [1] 7.895305
##
## [[4]]
## [1] 18.01667
##
## [[5]]
## [1] -80
##
## [[6]]
## [1] -70
##
## [[7]]
## [1] -10
##
## [[8]]
## [1] 0lapply(samples_ow2, function(l) mean(l[l$oil_content=="wet",]$utility))## [[1]]
## [1] 37.05196
##
## [[2]]
## [1] 46.96654
##
## [[3]]
## [1] -13.11342
##
## [[4]]
## [1] -3.081083
##
## [[5]]
## [1] 40
##
## [[6]]
## [1] 50
##
## [[7]]
## [1] -10
##
## [[8]]
## [1] 0lapply(samples_ow2, function(l) mean(l[l$oil_content=="soak",]$utility))## [[1]]
## [1] 195.2372
##
## [[2]]
## [1] 204.8781
##
## [[3]]
## [1] -4.921906
##
## [[4]]
## [1] 5.022908
##
## [[5]]
## [1] 190
##
## [[6]]
## [1] 200
##
## [[7]]
## [1] -10
##
## [[8]]
## [1] 0lapply(samples_ow2, function(l) mean(l[l$seismic_results=="ns",]$utility))## [[1]]
## [1] -20.49632
##
## [[2]]
## [1] 28.83352
##
## [[3]]
## [1] 3.597798
##
## [[4]]
## [1] 9.127434
##
## [[5]]
## [1] -35.31723
##
## [[6]]
## [1] 20.17144
##
## [[7]]
## [1] -10
##
## [[8]]
## [1] 0lapply(samples_ow2, function(l) mean(l[l$seismic_results=="os",]$utility))## [[1]]
## [1] 21.1454
##
## [[2]]
## [1] 28.40854
##
## [[3]]
## [1] -2.147717
##
## [[4]]
## [1] 9.150114
##
## [[5]]
## [1] 11.18149
##
## [[6]]
## [1] 19.48288
##
## [[7]]
## [1] -10
##
## [[8]]
## [1] 0lapply(samples_ow2, function(l) mean(l[l$seismic_results=="cs",]$utility))## [[1]]
## [1] 77.92582
##
## [[2]]
## [1] 29.04507
##
## [[3]]
## [1] -6.31717
##
## [[4]]
## [1] 9.102018
##
## [[5]]
## [1] 72.70859
##
## [[6]]
## [1] 20.93013
##
## [[7]]
## [1] -10
##
## [[8]]
## [1] 0lapply(samples_ow2, function(l) mean(l[l$extra_oil_content=="nr",]$utility))## [[1]]
## [1] 9.777404
##
## [[2]]
## [1] 20.7558
##
## [[3]]
## [1] -30
##
## [[4]]
## [1] -20
##
## [[5]]
## [1] 30.84713
##
## [[6]]
## [1] 40.16802
##
## [[7]]
## [1] -10
##
## [[8]]
## [1] 0lapply(samples_ow2, function(l) mean(l[l$extra_oil_content=="lr",]$utility))## [[1]]
## [1] 84.55078
##
## [[2]]
## [1] 92.07723
##
## [[3]]
## [1] 0
##
## [[4]]
## [1] 10
##
## [[5]]
## [1] 72.1223
##
## [[6]]
## [1] 84.21297
##
## [[7]]
## [1] -10
##
## [[8]]
## [1] 0lapply(samples_ow2, function(l) mean(l[l$extra_oil_content=="hr",]$utility))## [[1]]
## [1] -15.38561
##
## [[2]]
## [1] -6.065667
##
## [[3]]
## [1] 20
##
## [[4]]
## [1] 30
##
## [[5]]
## [1] -46.2878
##
## [[6]]
## [1] -35.13437
##
## [[7]]
## [1] -10
##
## [[8]]
## [1] 0